The Social, Political and Economic Event Database Project (SPEED)

The Social, Political and Economic Event Database Project (SPEED)
SPEED is a technology-intensive effort to extract event data from a global archive of news reports covering the Post WWII era. It is designed to provide insights into key behavioral patterns and relationships that are valid across countries and over time. Within SPEED, event data is generated by human analysts using a suite of sophisticated tools to implement carefully structured and pretested protocols. These protocols are category-specific electronic documents that are tailored to the information needs of a particular category of events (civil unrest, property rights, electoral processes, etc.). SPEED data will produce insights that complement those generated by other components of the Societal Infrastructures and Development Project (SID) (constitutional data, archival data, survey-based data, etc.) because event data generates "bottom-up" observations from news reports. In generating these event data SPEED leverages tens of billions of dollars that have been invested in compiling news reports from throughout the world.
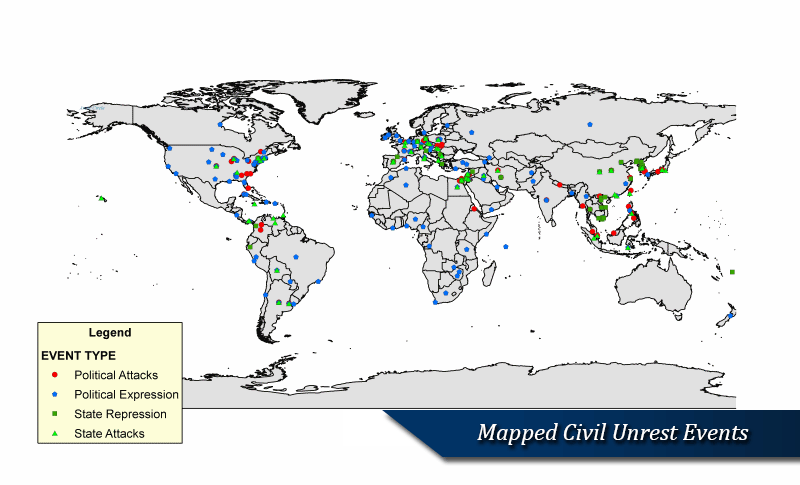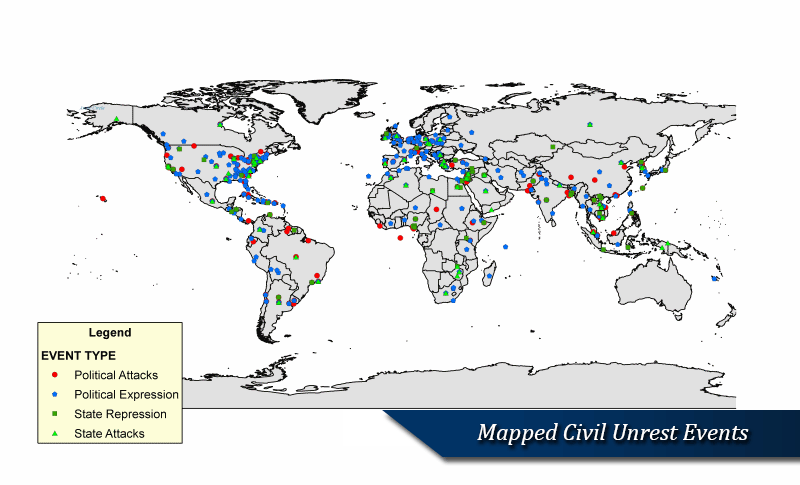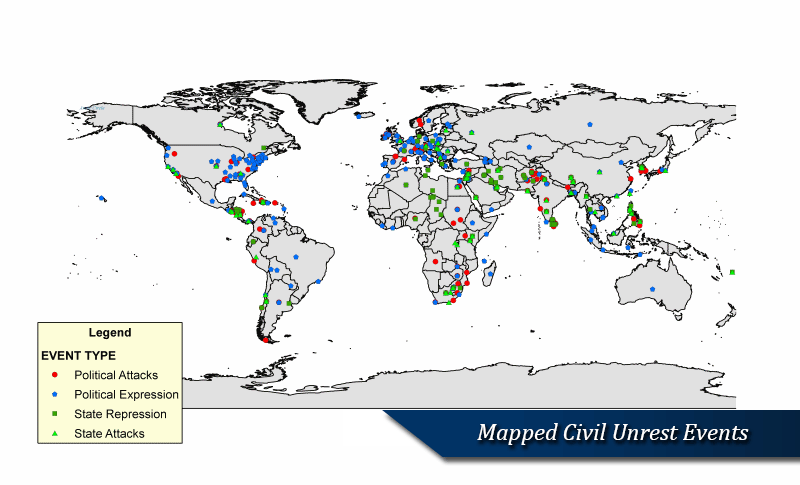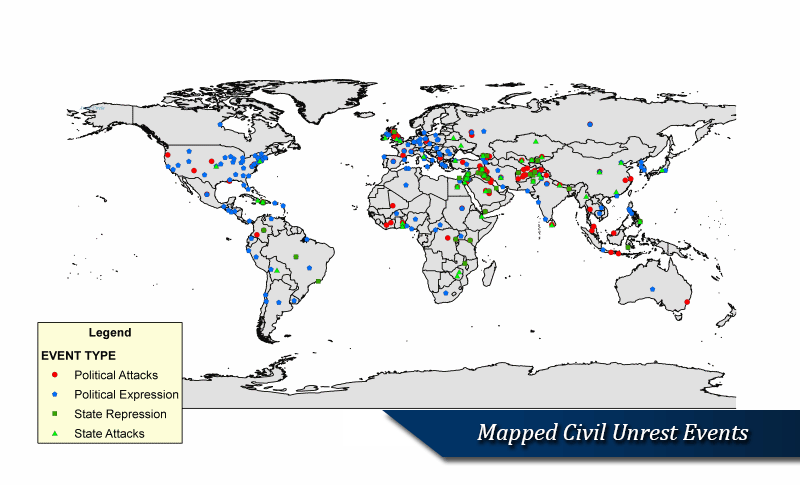
The SPEED project is a complex orchestration of many unique supporting components: assembling an archive of digitized news reports for virtually every country in the world January 1, 1946 to present; developing categories of events germane to SID's theoretical framework; devising efficient and reliable procedures to classify millions of news reports within the categorization scheme; identify relevant textual passages in each news report; and create efficient, reliable and technologically enabled procedures to extract information from news reports. This section outlines the core enabling components of the project, such as its Global News Archive, Classification Scheme, Classification Module, Text Annotation Module, and Information Extraction Tools.
Global News Archive
To meet the information needs of the SPEED project we assembled a comprehensive set of global news sources for the post-1945 period. Since 2006 our SEARCH program has been crawling across news websites (over 5,000 news feeds in 120 countries) several times each day, scraping news reports and storing them on our server. We are currently adding an additional 100,000 articles each day. Acquiring news sources before 2006, however, required a different approach. We were able to secure the complete historical archives of the New York Times and Wall Street Journal for the 1946-2006 period, which had been digitized. However, these were not deemed to have sufficient international coverage. Thus, we secured microfiche and microfilm records for two intelligence agency news services: the Foreign Broadcast Information Service (CIA) and the Summary of World Broadcasts (BBC). These contain millions of news articles and broadcasts that were translated into English from scores of languages. These news reports were derived from tens of thousands of news outlets and cover developments in every country in the world. To access the information in these sources, over 1,000 reels of microfilm and 50,000 microfiche had to be scanned and digitized. In addition, each individual report had to be "segmented" and joined with its header information (e.g. source, date, etc.). Thus, processing this information has required a multi-year effort. Adding these news reports, however, led to a highly inclusive global news archive of over 40M reports, which is growing on a daily basis.
Classification Scheme
Our events classification scheme emerged from the needs of the SID project and our assessment of the capacity of news reports to fill those information needs. Not every information need in a project such as SID is covered adequately by news reports. Moreover, there are some information needs that can be met by more efficient procedures than those required by SPEED (e.g., economic and demographic information). Thus, a great deal of time and effort was invested in identifying the types of information that could optimally be secured through an event analysis project such as SPEED. This process led to the development of an event classification scheme that was used to guide the subsequent phases of SPEED. The final version of the classification scheme includes events pertaining to such diverse topics as societal stability, human rights, electoral integrity, the supremacy of law, the security of property rights, the viability of governmental checks and balances, and the government's economic role. Each category within the classification has a multi-tier ontology of relevant events that is reflected in the design of category-specific protocols.
Classifying News Reports: The BIN Module
Assembling a global news archive and identifying relevant event categories are only preliminary steps in generating event data rigorously. An archive of over 40M news report requires automated techniques to identify reports with information about events that fall within the classification scheme, as well as to sort them into the appropriate category (societal stability, electoral integrity, property rights, etc.). To do this we developed an automatic text categorization program (BIN). BIN uses statistically based algorithms based on key words, word correlations, and semantic structures to identify and categorize relevant reports. BIN generates statistical probabilities that a news report belongs to a particular category within the classification scheme. A report gets assigned to a category if that probability is sufficiently high. Moreover, as reports often contain information on several different events, BIN has the capacity to sort a single report into different category-specific bins. BIN's algorithms were developed by using thousands of human-categorized reports to "teach" the computer to recognize the semantic attributes that characterize reports belonging to a specific category; it has proven to be very robust. Thresholds for inclusion were set relatively low, so as not to discard news reports with information on relevant events. Consequently, repeated tests examining random samples of discarded news reports (i.e., those not deemed relevant to any category within the classification scheme), suggest that BIN has a false negative rate of just 1%.
Text Annotation within Binned Reports: The EAT Module
Correctly identifying and electronically categorizing events is absolutely essential to generating event data in a project of SPEED's scope. But the large amount of text that has to be processed - even with perfectly binned reports - gives rise to another set of formidable cognitive challenges to information extraction. To meet these challenges we developed an "event annotation tool" (EAT) that annotates "binned" news reports. EAT employs a variety of computational procedures rooted in the field of natural language processing (NLP) to highlight text that contains relevant information about events belonging to a specific event ontology. Training data coded by humans educate the computer as to the type of information that is relevant. Generating a requisite level of accuracy with a tool such as EAT requires an extended iterative process between computer-generated models and human coders. EAT is currently in an advanced developmental stage; when properly calibrated, EAT annotations will greatly enhance the efficiency, accuracy and reliability of information extraction within SPEED.
Information Extraction: The EXTRACT Suite of Programs
To extract large sets of complex information from the millions of binned reports we developed EXTRACT, a suite of electronic modules that facilitates the work of human operators. At the core of EXTRACT is a set of category-specific protocols and a web-based interface that integrates the digitized news reports and category-specific protocols. The protocols are carefully designed and pretested and the human operators are extensively trained in both the protocol and EXTRACT's modules. Moreover, EXTRACT provides for on-going quality control: it can feed a set of pre-coded "test" articles to all operators and generate reports on the accuracy and reliability of operators by question set. The EXTRACT program also contains a number of modules to extract information efficiently and accurately. A calendaring module facilitates the ascertainment of the date upon which an event occurred. The geocoder module uses NLP techniques in conjunction with two large geospatial databases containing 8M place names (GIS, GNIS) to identify the event's location. In addition, EXTRACT employs chaining technologies to link related events that are contained in different news reports (antecedent events, post-hoc reactions, etc.). NLP techniques are also used with lexicons of social group names (religious, ethnic, racial, tribal, nationality, insurgent, etc.) to capture the identity of event participants (initiators, targets, victims, etc.) and external facilitators/collaborators (other nations, NGOs, etc.).
Event collection is through a series of survey instruments known as protocols that translate textual news reports into codified event records. The event ontology that structures SPEED's Societal Stability Protocol was developed during a year-long pretest involving the analysis of thousands of news reports. There are six tier-1 categories that structure the ontology: political expression events, politically motivated attacks, destabilizing state acts, political reconfiguration events, mass movements of people and cataclysmic events. These basic categories capture a wide range of destabilizing activity. Moreover, each of these has at least one tier of categories below the first tier and some have as many as three additional tiers. For example, political expression events include everything from verbal and written expressions to demonstrations, strikes and symbolic expressions; the latter include a host of different acts that vary in their potency. Politically motivated attacks include spontaneous mass attacks (riots, brawls), extraordinary attacks (assassinations, suicide attacks, kidnappings, executions, etc.), garden variety attacks on people and property, and organized mass attacks - as well as unexecuted attacks (conspiracies and attempted attacks). Destabilizing state acts include extraordinary actions (censorship, states of emergencies, curfews, disruptions of communication channels, etc.), armed attacks, coercive actions, and a number of ordinary state actions performed with malice (punitive dismissals, facility closures, service suspensions, trespasses, etc.).
The rationale for using such an extensive and refined ontology to identify and extract information on events is that it provides the means to generate insights into the dynamics of instability. Insurgencies, civil wars and political coups are not the only type of disruptive societal behavior. Moreover, as a number of scholars have long argued (Gurr, 1970, Schwartz, 1970, Hopper, Singer, 1972), they are the endpoints of an extended and often convoluted process, one replete with critical junctures, missed opportunities, and strategic moves. Most situations that have the potential to evolve into extended violent episodes do not; others that could have been short-circuited were not. Capturing events such as speeches, demonstrations, symbolic actions, isolated violent attacks, and state exercises of coercive force makes it possible to identify escalatory patterns that can yield insights into the dynamics of conflict across contexts. This makes it possible to both gauge the impact of climate change on conflict as well as provide insights into how violent conflict can be anticipated and avoided.
The extensive amount of event-specific information collected by SPEED's Societal Stability Protocol is also useful in enhancing our understanding of how episodes of destabilizing events evolve, and perhaps escalate, over time. The protocol includes over 350 queries though most are relevant only to specific event subtypes and are highly branched. Indeed, 97% of the protocols questions are response-activated by over 600 branching commands embedded within EXTRACT. These queries are designed to provide event-specific information on who, what, how, where, when and why:
- Who
- Initiators; Targets/Victims
- International involvement
- What
- Event type
- Impacts (people, property, society)
- Consequences (for initiators)
- Reactions (to event)
- Subsequent events
- How
- Weapon, modes of expression, type of natural force
- Where
- Geo-spatial location, geo-physical setting
- When
- Date
- Why
- Societal context
- Attributed origins
For example, with respect to "who" is involved in the event, the protocol captures information on initiators, targets and victims. An extensive pretest led to the development of list sets that captures thirty-seven types of non-governmental actors (social groups, workers, civic leaders, clergy, etc.) and twenty-three types of government actors (public safety officers, soldiers, bureaucrats, presidents, dictators, generals, etc.). Lexicon-based modules provide a uniform method of capturing the identity of social, political and insurgent groups, if they are involved in the event as initiators, targets or victims. Information is also recorded on the number of individuals involved. Other parts of the protocol pertain to the involvement of foreign countries or international organizations. If either type of entity is involved, a lexicon-based module captures it name. With respect to "what" the event entailed, the protocol provides for information on both the multi-tier event type and its scope/intensity. A set of scope/intensity question sets capture information on the number of initiators and victims as well as its effects (e.g., impact on individuals/communities/society, property damage, etc.). Another dimension to "what" the event entailed deals with post-event developments. The protocol has question sets to capture the direct consequences for initiators, the post-hoc reactions (condemnations, boycotts, retaliatory attacks, strikes, protests, etc.) of entities not involved in the event (governments, civic groups, international organizations, etc.). Finally, EXTRACT's LINK module creates electronic links between a focal event and related events (attacks that led to a protest demonstration, repressive government act that precipitated a violent attack, an attack by Sunnis on Shiites that led to an attack on a Sunni marketplace.
Within the "how" category, the protocol captures information on weapons used (if any), modes of expression, and types of natural forces. Geo-spatial information (latitude and longitude) is provided on "where" the event occurred; a list set containing types of geophysical locations (market, residence, recreational area, house of worship, airspace, etc.) provides additional information on where the event occurred that can be useful in providing important insights into an event. Date information is collected on when the event occurred as well as how long it lasted (where relevant). Finally, with respect to "why" an event occurred, an extensive amount of information is collected on the societal context of the event (on-going turmoil, penumbra or anniversary of a symbolically important happening, war time, etc.) as well as its attributed origins (dissatisfaction with government, ethnic animosities, ideological concerns, basic human needs, etc.).
A Progressive Supervised-learning Approach to Generating Rich Civil Strife Data Sociological Methodology, Vol. 45 No. 1, August 2015
"Big data" in the form of unstructured text poses challenges and opportunities to social scientists committed to advancing research frontiers. Because machine-based and humancentric approaches to content analysis have different strengths for extracting information from unstructured text, we argue for a collaborative, hybrid approach that combines their comparative advantages. The notion of a progressive supervised-learning approach that combines data science techniques and human coders is developed and illustrated using the Social, Political and Economic Event Database (SPEED) project's Societal Stability Protocol (SSP). SPEED's rich event data on civil strife reveals that conventional machine-based approaches for generating event data miss a great deal of within-category variance, while conventional human-based efforts to categorize periods of civil war or political instability routinely mis-specify periods of calm and unrest. To demonstrate the potential of hybrid data collection methods, SPEED data on event intensities and origins are used to trace the changing role of political, socio-economic and socio-cultural factors in generating global civil strife in the post-World War II era.
The SPEED Project's Societal Stability Protocol: An Overview - This document provides an introduction to, and an overview of, the SPEED Project's Societal Stability Protocol (SSP). The SSP's aim is to generate event data that will advance our understanding of civil unrest in the post-WWII era. The SSP's focus is on human-initiated destabilizing events, which are defined as happenings that unsettle the routines and expectations of citizens, cause them to be fearful, and raise their anxiety about the future. The SSP's destabilizing event ontology contains four Tier 1 categories (political expression events, politically motivated attacks, disruptive state acts, and political power reconfigurations). Because of the enormous variations that exist across and within these broad categories, advancing our understanding of civil unrest requires a good deal of event-specific information (who, what, where, when, how, why, etc.). The SSP was created to collect this information and the purpose of this paper is to provide an overview of its design and structure.
SPEED's Societal Stability Protocol and the Study of Civil Unrest: An Overview and Comparison with Other Event Data Projects - SPEED is a technology-intensive effort to collect a comprehensive body of global event data for the Post WWII era. It is a protocol-driven system that was designed to provide insights into key behavioral patterns and relationships that are valid across countries and over time. SPEED's Societal Stability Protocol has been the focus of most developmental work at this stage in SPEED's development. There are a number of highly regarded event data projects that exist throughout the world that have also been designed to shed light on societal stability; this document compares SPEED with a number of the more prominent ones. It is organized into two sections. The first describes SPEED's distinctive features: its global news archive, the comprehensiveness of its event ontology, its search technologies, the richness of the information collected on individual events, and its training and quality control capacities. The second section compares SPEED with other event projects.
Transforming Textual Information on Events into Event Data within SPEED - Creating a valid and reliable body of event data requires meeting a number of challenges (clearly defining the events to be studied, developing reliable sources of information on those events, identifying source documents with relevant information, etc.). The fact that most event data projects, including SPEED, use news reports as the source of information on events generates an additional set of challenges. Some of the most important of these are cognitive challenges involved in transforming textual information contained in news reports into event-centered information. This document outlines these challenges and how they are addressed within the SPEED project.
Automatic Document Categorization for Highly Nuanced Topics in Massive-Scale Document Collections: The SPEED BIN Program - This whitepaper offers a brief introduction to the BIN system of the Social, Political and Economic Event Database (SPEED) project. BIN provides automatic document categorization of highly nuanced topics across massive-scale document archives. The BIN system allows a group of trained human editors to present the computer with a relatively small collection of hand-categorized documents representing a given topic. It uses the semantic characteristics of these documents to develop a statistical model that is capable of identifying other documents on that same topic from the Cline Center global news archive, which contains tens of millions of news reports. Tests have shown that BIN has a false negative (incorrectly discarded relevant documents) rate of 1-4%. This paper outlines the basic premise and motivation behind BIN, its development, and its application to the SPEED project.
Definitions of Destabilizing Events in SPEED - This document is designed to provide operators of the EXTRACT suite of programs with an accessible guide to the definition and meaning of events intended to be captured in the Societal Stability Protocol (SSP) with the Social, Political and Economic Event Database (SPEED) project. It is a companion document to "The SPEED Project's Societal Stability Protocol: An Introduction for Operators of the EXTRACT Suite of Programs." Creating an archive of reliable event data using a large number of operators over an extended period of time requires that operators employ shared meanings of the events. This document is intended to provide the basis for that shared meaning.
Gauging Civil Unrest with SPEED Data: The Societal Stability Protocol and the Intensity of Civil Unrest - Destabilizing events - whether they are political expression events, politically motivated attacks, disruptive state acts, or some other manifestation of discontent - can vary enormously in their intensity. It is important to capture differences in intensity because they can affect the impact of seemingly similar events or the reactions of others to those events. The SPEED project's Societal Stability Protocol captures a great deal of information on what can be considered "intensity indicators." These indicators include such things as the type of weapons employed, the number of protesters, the number of people killed/ injured, and the number of people arrested. Developing composite measures of intensity is complicated because different sets of intensity indicators are relevant for different types of events. This document reports the procedures that were used to derive intensity measures for the different categories of destabilizing events recognized in SPEED's Societal Stability Protocol.
The Origins of Destabilizing Events - Destabilizing events such as those captured by SPEED's Societal Stability Protocol (SSP) - protests, politically motivated attacks, disruptive state acts, mass movements of people, irregular transfers of political power - do not happen in a vacuum. Rather, most are rooted in something. Developing the capacity to identify the origins destabilizing events can potentially lead to important advances in our understanding of civil unrest. It can also broaden the utility of event data and greatly enhance their explanatory potential. This document outlines the definitions and rationale for the Event Origins fields in the SPEED Societal Stability Protocol.
The Quality and Reliability of Data Generated by SPEED's Societal Stability Protocol: Mechanisms and Tests - Extracting information from global news reports in the post WWII era makes it possible to capitalize on the billions of dollars that have been invested in reporting on newsworthy events during that timeframe. It also offers unprecedented opportunities to improve our understanding of important societal developments and processes. Developing empirically well-grounded insights into these matters, however, requires that the data extracted from news reports are robust and dependable. This paper analyzes the data generation process employed by SPEED's Societal Stability Protocol. We first outline our approach to providing for quality control in data generation and then we discuss our approach to gauging data reliability. We also report the results of several reliability tests that have been conducted 2009. The results indicate that our coders meet basic social science standards. Coders reliably identify 72-85% of all relevant events, and accurately code the information on those events 75-89% of the time.
SPEED's Global News Archive: An Overview and Assessment - The SPEED’s project capacity to contribute to advances in social research is bounded by the breadth and depth of its information base and the tools employed to mine data from that information base. If events are not captured in an information base – or identified using data mining tools – then they cannot be used for research purposes. Consequently, we employed a range of technologies to enhance both the scope of the information base and our ability to mine relevant data embedded in it. The first section of this document provides a brief overview of SPEED’s global news archive. While the techniques used to identify news reports relevant to a particular SPEED protocol are reported elsewhere,1the remaining two sections assess the adequacy of SPEED’s information base and the power of it data mining tools. These assessments focus on destabilizing events that are relevant to SPEED’s Societal Stability Protocol (SSP). The adequacy of SPEED’s information base is gauged by comparing it to Armed Conflict Location and Events Dataset project, or ACLED (Raleigh et al. 2010). ACLED focuses largely on African countries beginning in the mid 1990’s, but it draws from an encompassing set of news sources, including local ones. The power of SPEED’s data mining tools is assessed by comparing SSP event counts with the World Handbook of Social and Political Indicators (WHSPI, Taylor and Jodice 1983), which employs wholly human-centric procedures to identify relevant events. We find SPEED’s information base to be comparable to ACLED’s and SPEED’s data mining tools to be far superior to WHSPI’s.
Demarcating Episodes of Civil Strife: An Inductive, Iterative Approach - This document outlines the procedures and criteria used to delineate episodes of civil strife for 164 countries in the world for the period from January 1, 1946 to December 31, 2005. Prior research has been handicapped by a lack of data on civil strife events and defensible criteria for differentiating major episodes of civil strife from others. We use an inductive, iterative approach that builds on the work of the Political Instability Task Force and the Social, Political and Economic Event Database project (SPEED). We integrate event data from SPEED’s Societal Stability Protocol (SSP) with PITF episodes, which are organized on a country-month basis. An inductive approach is used in conjunction with the integrated data because concrete standards are not available for identifying major episodes of strife and no well-developed body of theory exists from which these standards can be deduced. An iterative approach is needed because the integration of SSP data with the PITF episodes revealed that PITF’s use of subjective, holistic judgments in demarcating the temporal boundaries of their episodes introduced a great deal of measurement error. To enhance the utility of PITF’s episodes, the integrated SSP data was used to de-construct PITF episodes and then re-specify them. The re-specified episodes provide the basis for inductively generating more refined criteria for identifying major episodes of civil strife as well as less disruptive, yet still noteworthy, episodes.
The first main section introduces the approach used to derive the criteria for identifying major episodes of strife. The second main section applies the inductively derived criteria to the countries being studied.
Media Data and Social Science Research: Problems and Approaches - News media provide a unique source of information on important societal developments, both contemporary and historical. Consequently, over the past forty years, social scientists have attempted to utilize media data to study important questions in a number of fields. But these efforts have been subjected to sobering critiques in an on-going debate over the utility of media data in social science research. The advent of the Information Age has both raised the stakes of this sustained debate and restructured it. Over the past several decades we have seen the emergence of the Internet, the rise of news websites, the widespread availability of digitized news reports, and the creation of 24x7 news stations. These developments have led to unprecedented increases in the volume, scope and accessibility of news reports. Advances in data science and computational capacity have greatly enhanced the ability of researchers to process information embedded in those news reports.
The confluence of these developments has laid the groundwork for third-generation media data projects that have the potential to generate major advances in several fields of research. But the implications of these Information Age developments for the sustained debate over the utility of media data have not been explored and, without a better understanding of those implications, the potential of third-generation projects may never been fully realized. Thus, this paper re-examines the on-going debate over media data in light of these recent developments. We begin by summarizing the key issues raised by critics and asserting that they identify three sets of problems with media data: a comprehensiveness problem, an identification problem, and a distortion problem. In the second main section of the paper we decompose each of these issues and assess their implications for contemporary research employing media data. In this assessment we focus on civil strife research, but most of the main points pertain beyond this field. We also discuss the potential for the remediation of the problems that posed serious threats to the utility of media, with an emphasis on third-generation research efforts like the Social, Political and Economic Event Data (SPEED) project.